Компании AMD и NVIDIA сегодня представили новые графические решения для высокопроизводительных вычислений, связанных с работой алгоритмов искусственного интеллекта. И если в случае NVIDIA речь идёт об обновлении уже существующего ускорителя A100, которому увеличили объём памяти и её пропускную способность, то AMD представила совершенно новое решение в виде ускорителя Instinct MI100 на базе новой архитектуры CDNA.

Источник изображения: NVIDIA
Новая версия графического ускорителя NVIDIA A100, как и оригинальная основана на базе архитектуры Ampere. От предыдущей версии новинку отличает увеличенный с 40 до 80 Гбайт объём памяти HBM2e, а также повысившаяся с 1,555 до 2 Тбайт/с пропускная способность. Остальные характеристики обеих версий ускорителя совпадают.

Источник изображения: NVIDIA

Источник изображения: NVIDIA
На данный момент новая версия A100 представлена только в форм-факторе SXM3, поэтому предназначается для использования в составе собственной вычислительной платформы NVIDIA DGX, а также в составе HGX-платформ от партнёров. Последние представят в начале будущего года специальные наборы для интеграции новой версии A100 в свои существующие решения, включая варианты, поддерживающие установку 4 и 8 ускорителей.

Источник изображения: AMD
Новинке от NVIDA придётся конкурировать против совершенно нового решения компании AMD — вычислительного графического ускорителя Instinct MI100, построенного на базе 7-нм архитектуры CDNA. В отличие от архитектуры RDNA, которая используется в игровых и профессиональных решениях, направленных, на работу с рендерингом, основной профиль CDNA — высокопроизводительные вычисления и работа с алгоритмами искусственного интеллекта.

Источник изображения: AMD
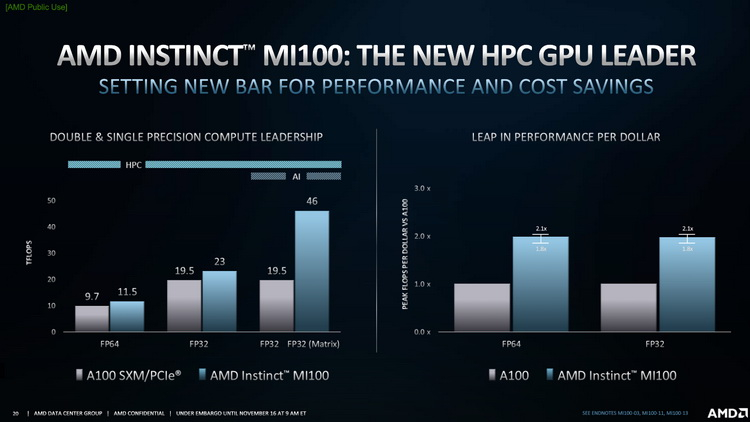
AMD Instinct MI100 предназначен для работы с интерфейсом PCIe 4.0 x16 (64 Гбайт/с). В составе GPU Instinct MI100 используются 120 исполнительных блоков (Compute Units), в которых содержатся новые блоки для матричных операций, использующиеся в задачах по ускорению вычислений, связанных с ИИ-алгоритмами. По словам AMD, новые блоки работают не в ущерб классическим вычислениям. Например, пиковая производительность в FP64-приложениях составляет 11,5 Тфлопс, а для FP32 она ровно в два раза больше — 23 Тфлопс, что выше показателей, заявленных для NVIDIA A100.

Источник изображения: AMD
Однако в тех же bfloat16-вычислениях Instinct MI100 от AMD проигрывает конкуренту — 92,3 Тфлопс против 312 Тфлопс. Справедливости ради стоит отметить, что здесь речь идёт о сравнении с SXM-версией ускорителя NVIDIA A100. PCIe-версия ускорителя от NVIDIA в силу более низкого энергопотребления в реальных задачах может быть несколько медленнее. В свою очередь Instinct MI100 на данный момент представлен только в форм-факторе полноразмерной PCIe-карты с уровнем потребления 300 Вт.
AMD Instinct MI100 оснащён 32 Гбайт памяти HBM2 с пропускной способностью 1,23 Тбайт/с. Для сравнения, оригинальная версия NVIDIA A100 имеет на борту 40 Гбайт памяти HBM2e с пропускной способностью 1,555 Тбайт/с. Благодаря наличию трёх интерфейсов Infinity Fabric (IF) с пропускной способностью по 92 Гбайт/с (суммарно 276 Гбайт/с) можно объединить в связку до четырёх ускорителей Instinct MI100, работающих по схеме «каждый-с-каждым». При этом уровень пропускной способности не зависит от того, к каким интерфейсам (PCIe 3.0 или 4.0) подключён набор из Instinct MI100. У той же PCIe-версии NVIDIA A100 имеется только один интерфейс NVLink, позволяющий объединить только две карты. Однако пропускная способность при этом выше и составляет 600 Гбайт/с.
По словам AMD, её новое решение в 1,8–2,1 раза привлекательнее по соотношению показателя «производительность на доллар», чем у NVIDIA с её A100.
Источник изображения: AMD
Первыми системами, которые получат новые вычислительные графические ускорители AMD Instinct MI100 станут Dell PowerEdge R7525, Gigabyte G482-Z54, HPE Apollo 6500 Gen10 Plus и Supermicro AS-4124GS-TNR. Отмечается, что некоторые партнёры компании уже получили новые ускорители, а также системы на их основе для оценки производительности и адаптации программного обеспечения.
Более подробно про анонсы вычислительных графических ускорителей NVIDIA A100 и AMD Instinct MI100 можно прочитать на нашем дочернем ресурсе ServerNews.
Источники: